import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import statsmodels.formula.api as smf
# Column positions from the codebook (0-indexed start, end)
colspecs = [
(0, 3), (4, 5), (6, 7), (8, 9), (10, 11), (12, 13), (14, 15),
(16, 17), (18, 19), (20, 21), (22, 24), (25, 30), (31, 36),
(37, 42), (43, 48), (49, 54), (55, 60), (61, 62), (63, 68),
(69, 70), (71, 76), (77, 82), (83, 88), (89, 94), (95, 100),
(101, 103), (104, 106), (107, 108), (109, 110), (111, 117),
(118, 120), (121, 126), (127, 132), (133, 138), (139, 144),
(145, 150), (151, 156), (157, 158), (159, 160), (161, 166),
(167, 172), (173, 178), (179, 184), (185, 190), (191, 193), (194, 196)
]
col_names = [
"SHEET", "CHAIN", "CO_OWNED", "STATE", "SOUTHJ", "CENTRALJ", "NORTHJ",
"PA1", "PA2", "SHORE", "NCALLS", "EMPFT", "EMPPT", "NMGRS", "WAGE_ST",
"INCTIME", "FIRSTINC", "BONUS", "PCTAFF", "MEALS", "OPEN", "HRSOPEN",
"PSODA", "PFRY", "PENTREE", "NREGS", "NREGS11", "TYPE2", "STATUS2",
"DATE2", "NCALLS2", "EMPFT2", "EMPPT2", "NMGRS2", "WAGE_ST2", "INCTIME2",
"FIRSTIN2", "SPECIAL2", "MEALS2", "OPEN2R", "HRSOPEN2", "PSODA2",
"PFRY2", "PENTREE2", "NREGS2", "NREGS112"
]
df = pd.read_fwf("../../njmin/public.dat", colspecs=colspecs, names=col_names, na_values=".")
# Create the key variables
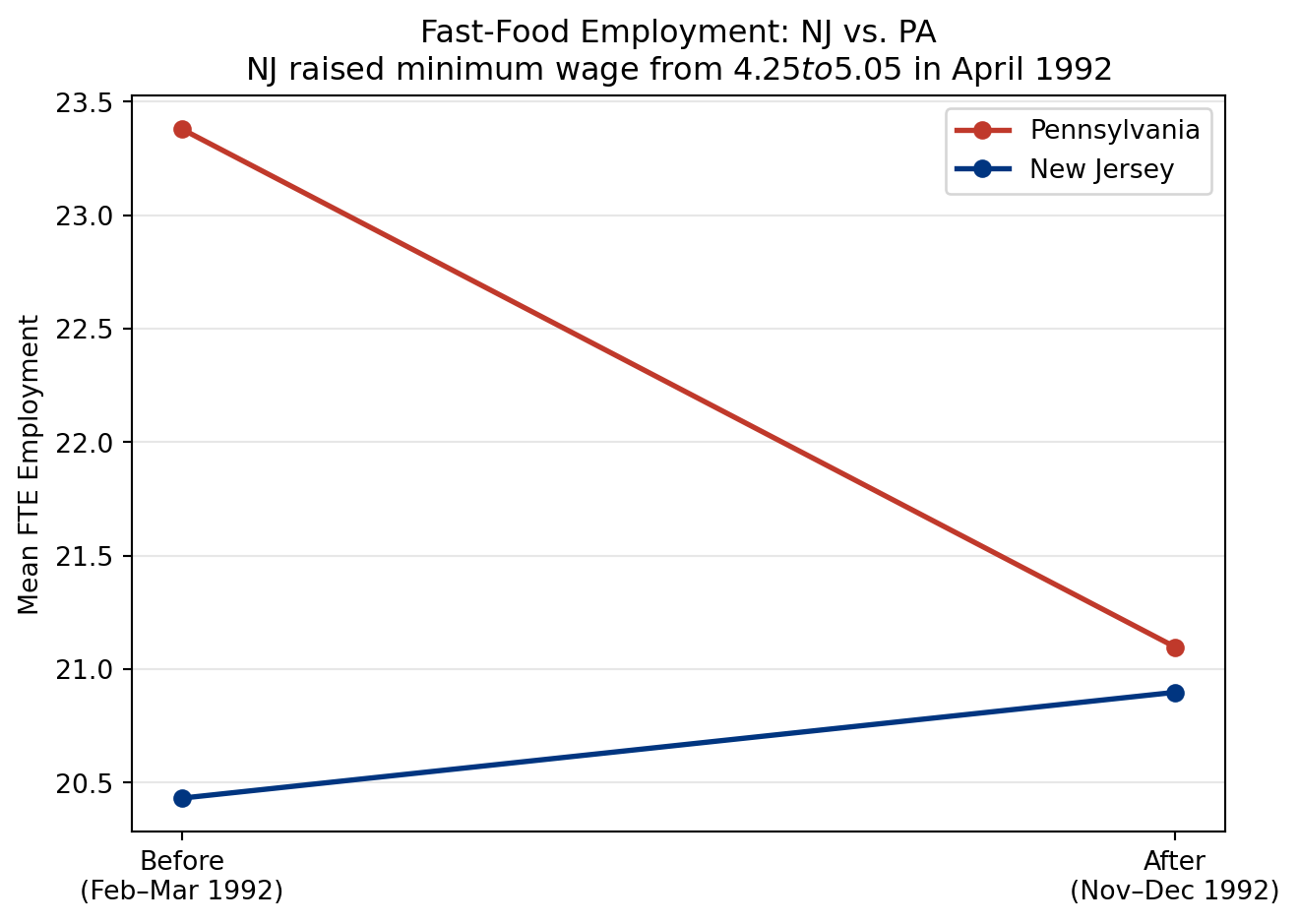
df["nj"] = df["STATE"] # 1 = New Jersey, 0 = Pennsylvania
# FTE employment = full-time + 0.5 * part-time + managers
df["fte_before"] = df["EMPFT"] + 0.5 * df["EMPPT"] + df["NMGRS"]
df["fte_after"] = df["EMPFT2"] + 0.5 * df["EMPPT2"] + df["NMGRS2"]
df["change_fte"] = df["fte_after"] - df["fte_before"]
# Meal price = soda + fries + entree
df["meal_price"] = df["PSODA"] + df["PFRY"] + df["PENTREE"]
df["pct_ft"] = df["EMPFT"] / df["fte_before"] * 100
# Drop stores missing employment data in either wave
df = df.dropna(subset=["fte_before", "fte_after"])
print(f"Stores in sample: {len(df)}")
print(f" Pennsylvania: {(df['nj'] == 0).sum()}")
print(f" New Jersey: {(df['nj'] == 1).sum()}")